Static analysis of malicious PDFs
While we are still waiting for the patch and the malicious PDFs which exploit CVE-2009-4324 become more and more nasty, here's another quick excursion in dissecting and analyzing hostile PDF files. We'll take a closer look at the sample that fellow ISC Handler Bojan already analyzed, but will this time do a static analysis without actually running the hostile code.
$md5sum Requset.pdf
192829aa8018987d95d127086d483cfc Requset.pdf
$ls -ald Requset.pdf
-rw-r----- 1 daniel handlers 952206 2010-01-03 23:57 Requset.pdf
One of the tools that work very well to analyze PDFs is Didier Stevens' excellent script "pdf-parser.py" . Running pdf-parser.py -f Requset.pdf | more nicely dissects the PDF into its portions, and also de-compresses packed sections. Almost at the end of the output, we encounter Object #44:
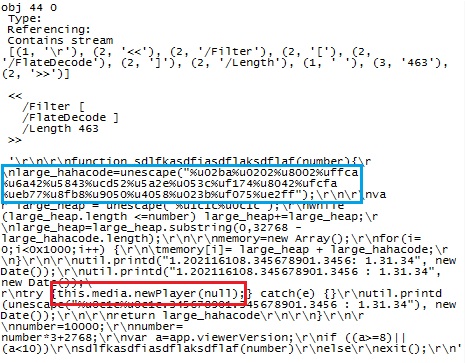
The code is included here as an image, to keep your anti-virus from panicking. The blue box marks the surprisingly short and efficient shell code block of only 38 bytes length that Bojan mentioned in his earlier diary. The red box marks the call to "media.newPlayer" with a null argument, which is a tell-tale sign of an exploit for CVE 2009-4324, the currently still unpatched Adobe vulnerability.
If all we wanted to know is whether this PDF is hostile, we can stop here: Yes, it is.
Taking a completely different tack on the same sample, a brute force method in analysis that often works, and also works in this case, is to check the sample for XOR encoded strings. XORSearch, another one of Didier Stevens' cool tools (URL) helps with this task. Let's check if the sample contains a XOR encoded representation of the string "http"
$ XORSearch Requset.pdf http
Found XOR 00 position E6340: http://www.w3.org/1999/02/22-rdf-syntax-ns#">.
Found XOR 00 position E63A9: http://ns.adobe.com/xap/1.0/">. <xmp:Modif
[...etc...]
Found XOR 85 position D870: http://www.w3.org/1999/02/22-rdf-syntax-ns#' xmlns
Found XOR 85 position D8A7: http://ns.adobe.com/iX/1.0/'>..<rdf:Description rd
Found XOR 85 position DAD4: http://ns.adobe.com/xap/1.0/mm/' xapMM:DocumentID=
Found XOR 85 position DB86: http://purl.org/dc/elements/1.1/' dc:format='appli
Found XOR 85 position 1054D: httpshellopencomMand.SoftwareMicrosoftActive
Well, a XOR with zero is not overly exciting, all this means is that the file contains these URLs in plain text. But a XOR with 85, and one that seems to be doing some sort of shell.open ... now that's intriguing. Let's simply XOR the entire PDF file with 0x85, and see what we get:
$cat Requset.pdf | perl -pe 's/(.)/chr(ord($1)^0x85)/ge' |strings | more
gfJV
w)pf
S>S2X4
[...etc...]
z<o*
7Fpo
!This program cannot be run in DOS mode.
L8Rich
M_*K
.text
`.rdata
Now lookie, it seems as if this PDF contains an embedded executable! And a bit further down in the de-xored file, we find
hepfixs.exe
baby
{38FC368D-A5D0-21DA-0404-080501030704}
cecon.flower-show.org
ws2_32
SOFTWAREClasseshttpshellopencomMand
SoftwareMicrosoftActive SetupInstalled Components
This gives us a potential domain name (cecon.flower-show. org), and also a ClassID. Searching for {38FC368D-A5D0-21DA-0404-080501030704} in Google, we find a recent ThreatExpert analysis http://www.threatexpert.com/report.aspx?md5=b0eeca383a7477ee689ec807b775ebbb that matches perfectly to what we found within this PDF.
Given the time later during my 24hr shift here at the ISC, I'll post another diary to take a look at other hostile PDF samples that we received. If you got any interesting potentially hostile PDFs, please send them in!


Comments
mike
Jan 7th 2010
1 decade ago
http://blog.didierstevens.com/2009/08/06/update-pdf-parser-version-0-3-5/
nogojoe
Jan 7th 2010
1 decade ago
/FlateDecode
/ASCIIHexDecode
/ASCII85Decode
The new version, to be published next week, adds support for:
/LZWDecode
/RunLengthDecode
Didier Stevens
Jan 8th 2010
1 decade ago
Excellent news. I just wanted to say thanks for a wonderful tool. Been using it for a while and it saves a lot of time.
mike
Jan 8th 2010
1 decade ago